Recent Publications
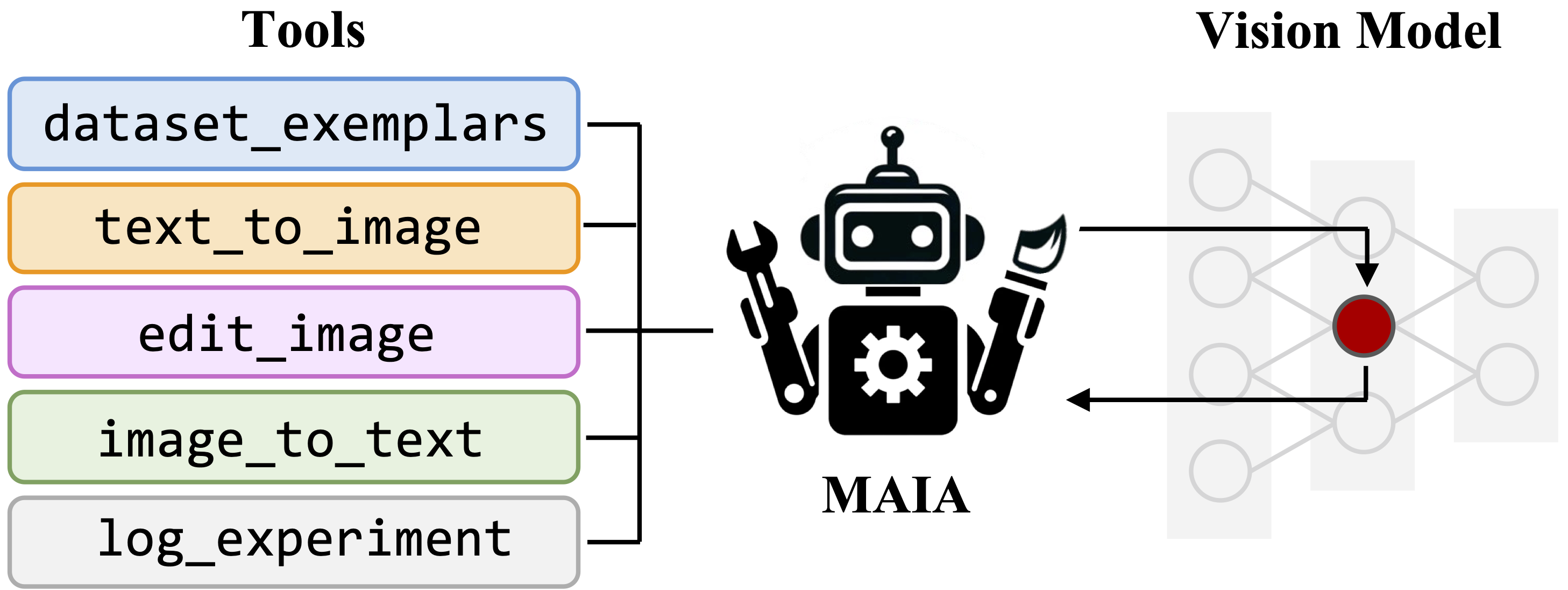
A Multimodal Automated Interpretability Agent
Tamar Rott Shaham*, Sarah Schwettmann*, Franklin Wang, Achyuta Rajaram, Evan Hernandez, Jacob Andreas, Antonio Torralba. ICML 2024.
An agent that autonomously conducts experiments on other systems to explain their behavior, by composing interpretability subroutines into Python programs.

FIND: A Function Description Benchmark for Evaluating Interpretability Methods
Sarah Schwettmann*, Tamar Rott Shaham*, Joanna Materzynska, Neil Chowdhury, Shuang Li, Jacob Andreas, David Bau, Antonio Torralba. NeurIPS 2023.
An interactive dataset of functions resembling subcomputations inside trained neural networks, for validating and comparing open-ended labeling tools, and a new method that uses Automated Interpretability Agents to explain other systems.
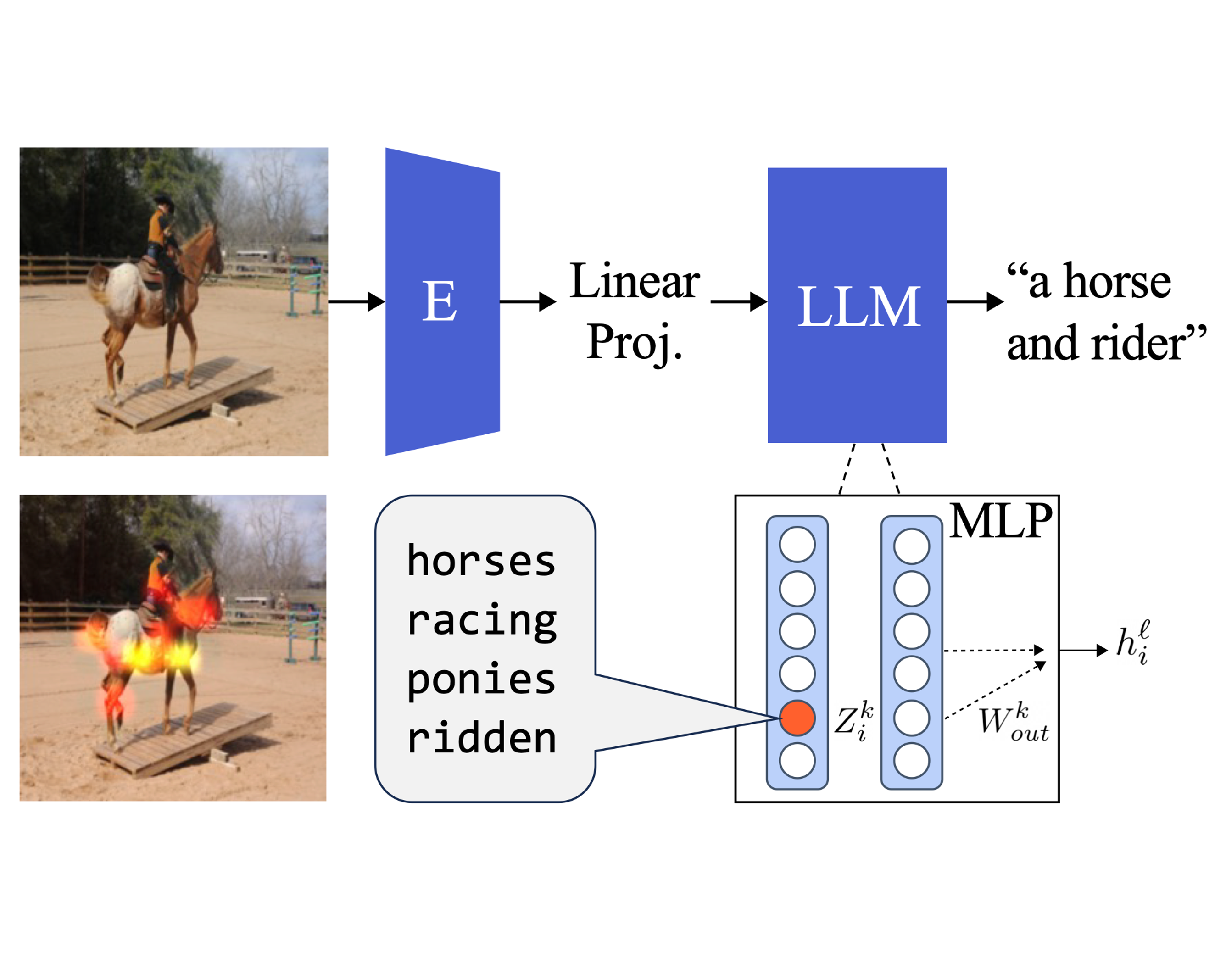
Multimodal Neurons in Pretrained Text-Only Transformers
Sarah Schwettmann*, Neil Chowdhury*, Samuel Klein, David Bau, Antonio Torralba. ICCV CVCL 2023 (Oral).
We find multimodal neurons in a transformer pretrained only on language. When image representations are aligned to the language model, these neurons activate on specific image features and inject related text into the model's next token prediction.

Natural Language Descriptions of Deep Visual Features
Evan Hernandez, Sarah Schwettmann, David Bau, Teona Bagashvili, Antonio Torralba, Jacob Andreas. ICLR 2022 (Oral).
We introduce a procedure that automatically labels neurons in deep networks with open-ended, compositional, natural language descriptions of their function.